Matthew Hipkin
Speed testing two third party XML parsers for FreePascal and Delphi
This article will be comparing the speed of two different third party XML parsers for FreePascal/Lazarus and Delphi. I don't intend on going into great details about features as this is purely to test the speed of parsing a simple XML file.
All testing was done using FreePascal 3.0.0 64-bit using FreeBSD 10.3 on an Intel Pentium P6200 CPU @ 2.27Ghz.
The XML files used in tests are available here (100,000 entries) and here (1,000,000 entries). The XML files are simple records of random names and ages generated using my Random Name Generator (also written using FreePascal).
The the source files for the test themselves can be downloaded here.
For the test I am simply parsing the XML contents into a TList using the following record type:
type
PPerson = ^TPerson;
TPerson = record
FirstName: String;
SurName: String;
Age: Byte;
end;
MYTHcode XML Parser
I have been using MYTHcode XML Parser for many years now, its very simple to use and has always served me well. Sadly, it hasn't been updated in a very long time so if you're trying to use it in a recent version of Delphi you'll probably find it churns out rubbish - it still works perfectly in Lazarus/FreePascal however.
The MYTHcode XML Parser uses a standard style while Next do structure that you're likely to see in other XML Parsers. The parser object is created with a string of the XML as a parameter, as a result the XML is loaded into a TStringList before being parsed.
xml := TStringList.Create; xml.LoadFromFile('namelist.xml'); parser := TXMLParser.Create(xml.Text); while parser.Next do begin if Parser.TagType = ttBeginTag then begin if Parser.Name = 'person' then new(person); if Parser.Name = 'firstname' then person^.FirstName := parser.ContentCode; if Parser.Name = 'surname' then person^.SurName := parser.ContentCode; if Parser.Name = 'age' then person^.Age := StrToIntDef(parser.ContentCode,0); end; if (Parser.TagType = ttEndTag) and (Parser.Name = 'person') then begin people.Add(person); end; end;
The process is quite simple: we check for an open tag, then within that we either create a new pointer to our record type or set the relevant variable to the right value. Because it parsed on a tag-by-tag basis we can always assume the <person> tag has been found in the loops before the 3 tags containing the actual values.
Finally, when we find the closing person tag we are safe to add our record to the TList.
Destructor LibXmlParser
LibXmlParser was a library I found recently when I was forced to use Delphi for a project instead of Lazarus. It does appear to be actively developed and has full support in modern Delphi versions aswell as FreePascal/Lazarus. I am using the non-Unicode version in this test.
This library takes a different approach to parsing where each loop within the scan only focuses on the current XML segment, so the first thing I had to do was create an enum to keep track of where I was within the XML:
type TCurrentTagType = (ttNone, ttFirstName, ttSurName, ttAge);
LibXmlParser does not require the XML to exist as a string before being parsed and can load direct from a file or buffer.
parser := TXMLParser.Create; parser.Normalize := true; parser.LoadFromFile('namelist.xml'); parser.StartScan; while parser.Scan do begin if Parser.CurPartType = ptStartTag then begin currentTag := ttNone; if Parser.CurName = 'person' then new(person); if Parser.CurName = 'firstname' then currentTag := ttFirstName; if Parser.CurName = 'surname' then currentTag := ttSurName; if Parser.CurName = 'age' then currentTag := ttAge; end; if Parser.CurPartType = ptContent then begin case currentTag of ttFirstName: person^.FirstName := parser.CurContent; ttSurName: person^.SurName := parser.CurContent; ttAge: person^.Age := StrToIntDef(parser.CurContent,0); end; end; if (Parser.CurPartType = ptEndTag) and (Parser.CurName = 'person') then begin people.Add(person); end; end;
As you can see in this parser I am having to use the enum to keep track of which tag I am inside of to extract the contents - whilst this is a perfectly valid method it doesn't "feel" natural to me and could turn in to a real nightmare when handling XML that has many fields.
The tests
First up I tested both parsers with an XML file containing 100,000 records:
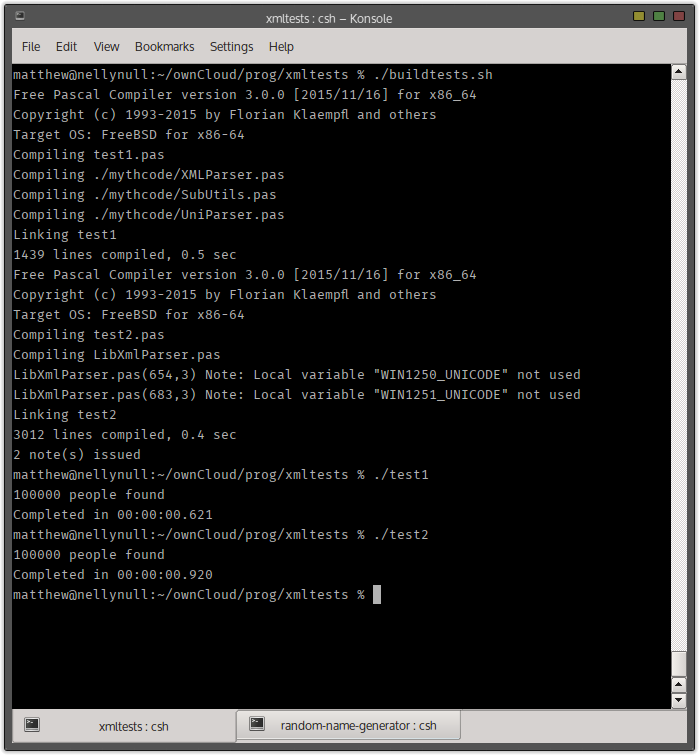
As you can see from the above screenshot MYTHcode XML Parser came out on top by almost half a second. I ran the test again with 1,000,000 records.
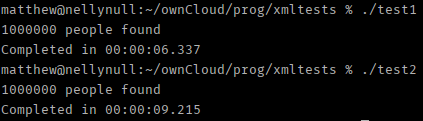
And again the MYTHcode parser came out on top although there were signs of it slowing down: LibXmlParser managed to keep its time almost exactly 10 times that of the first run but MYTHcode ran almost 1% slower with the larger dataset.
Conclusions
The MYTHcode parser, on the face of things, does seem to be faster than LibXmlParser although niether seem to have functionality for loading from streams which means the XML has to exist in memory before it can be parsed; this is an issue when using very large datasets. MYTHcode Parser's downside is that it doesn't appear to be actively maintained so if you're using a modern version of Delphi you'll definitely want to avoid.
Posted in tests on 2017-02-06 22:20:51
blog comments powered by Disqus