Matthew Hipkin
Blog
Cycle Every Possible RGB Colour
Posted 2019-05-21 21:41:06
Ever wanted to spit out every single RGB colour combination? Nope, niether have I. It's still a fun little programming challenge, and allows you to get more familiar with bitwise operations.
There are 16,777,216 possible colours (256 * 256 * 256) and we can extract the red, green and blue bits from each value as we iterate from 0 to 16,777,216 - this is the same as manually calculating the red, green and blue values on each loop iteration albeit much faster.
program cyclergb; {$mode objfpc}{$H+} uses Classes, SysUtils; procedure main; const TAB = #9; var i, r, g, b, maxcol: Integer; F: TextFile; begin maxcol := 256 * 256 * 256; AssignFile(F,'rgb.txt'); Rewrite(F); for i := 0 to maxcol-1 do begin r := (i shr 16) and $FF; g := (i shr 8) and $FF; b := i and $FF; writeln(F,r,TAB,g,TAB,b); end; CloseFile(F); end; begin main; end.
Upon completion this program would have produced a TSV file that is around 180mb in size (available here bzipped ~22mb) which you may find some use for.
Giving more colour to your ZX Spectrum!
Posted 2019-04-06 22:08:12
If the world wide web was a thing in the 1980s, my codeLib would probably look something like this....
The ZX Spectrum has some lovely vibrant colours, but what if you want to use something else?
Well, there is a cheeky way of getting other colours (in a limited fashion). For this example I have chosen the colour orange, because why not?
First up we are going to need a UDG!
10 FOR a=0 TO 7 STEP 2 20 POKE USR "P"+a,BIN 10101010 30 POKE USR "P"+a,BIN 01010101 40 NEXT a
If you haven't guessed by now we're going to use the checkered pattern with different PAPER and INK settings to give the effect of a different colour. So let's draw a big orange square on the screen!
50 FOR x=0 to 9 60 FOR y=0 to 9 70 PRINT AT x,y; PAPER 6; INK 2;CHR$ 159 80 NEXT y 90 NEXT x
Et voilà! If it's not quite orange enough, try altering the tuning on your TV so it's just a little bit out.
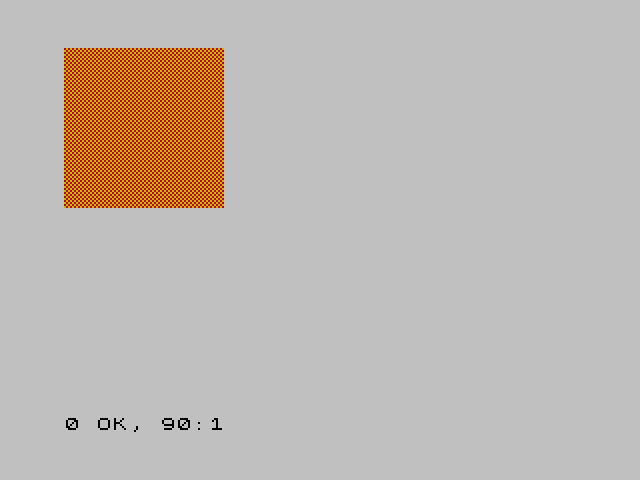
Why not try experimenting with giving your Speccy some more colours?
Into The Unknown
Posted 2019-01-03 22:21:23
Now that PasTinn is up and working, it's time to go beyond predicting digits that already exist in the semeion training dataset. What about some digits of my own?
Well, this is where things get interesting. I scribbled some numbers using a touch screen device and saved them, knocked them down to 16x16 and converted them into the same format as the training data - the neural network decided that only my zero looked remotely like a zero! I ran the data through the original C-based tinn aswell to make sure it wasn't my port (it wasn't).
I decided to take a closer look at the training data, so after creating a Delphi-based application to do just that (compiled download for Windows available here) I discovered that aside from some 1's all of the digits had no surrounding whitespace whereas my shrunken scribbles did.
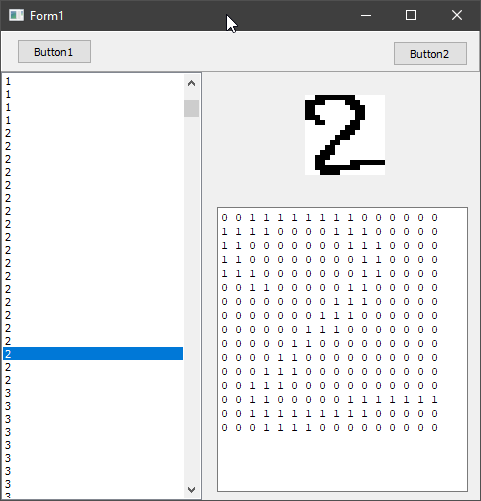
This required another tool (Lazarus this time - Windows download available here) to take my scribbles, remove outer whitespace and then stretch them into their 16x16 boxes for processing.
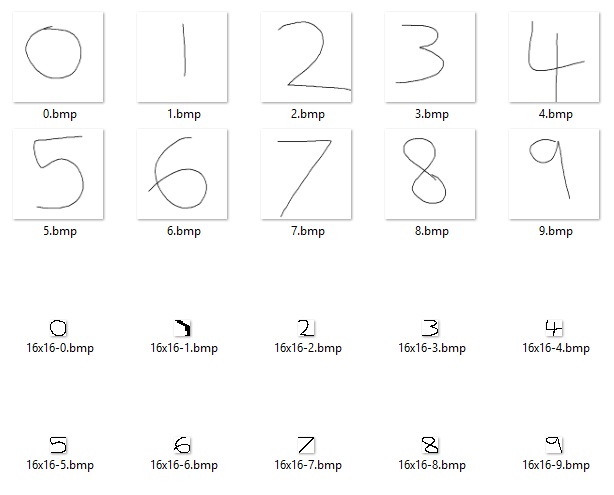
The output from this tool looked promising, aside from the 1 which had gone a bit wobbly. All that was left to do was to run this data through the neural network..
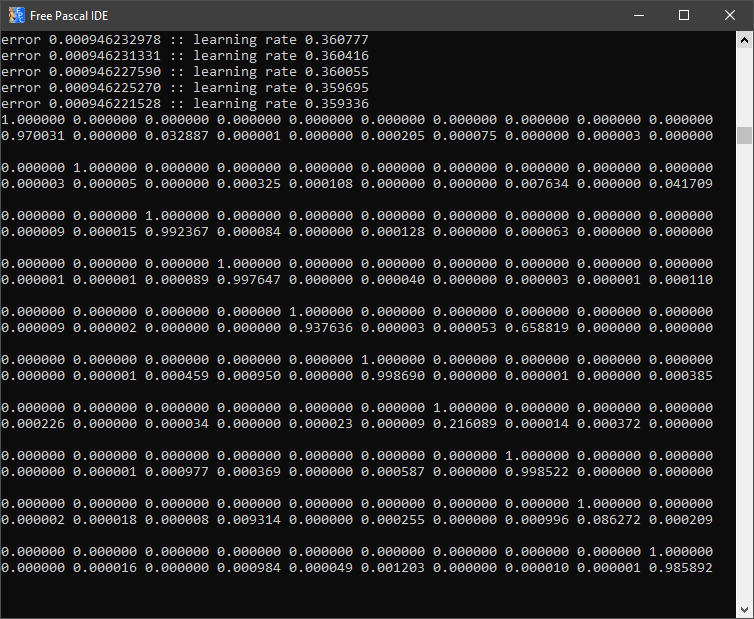
Not a bad outcome at all! I modified the test application included with PasTinn to loop all 10 digits found in the new test data file and the above is the result. 0: perfect! 1: yeah, well that went wobbly anyway. 2 to 5: perfect. 6? Not sure what's wrong with my 6 - obviously the neural network isn't a fan! 7 and 9 also perfect, but again with 8 it didn't have a clue.
In the above test, I had left the nhid value at 28 but ramped up the iterations to 512 - maybe some more fiddling will improve the accuracy of those two anomalies.
I think I'll post again in a few days with the results from various hidden layer/iteration combinations - might be interesting to see.
Class documentation is also now available for PasTinn.
Porting Tinn to Pascal
Posted 2018-12-19 21:11:03
Tinn (Tiny Neural Network) is a 200 line dependency free neural network library written in C. Being written in C and being less than 200 lines of code makes it a perfect candidate for porting over to Pascal.
Initially I did a direct port - function for function. It worked very nicely, but was much much slower than the original C version. I have started "Pascalifying" the code base - first job was turning it into a TObject descendant which sadly didn't increase speed all that much - still I'm sure there is plenty more optimisation to be done. Oddly enough I've had the best results from Delphi 7!
If you're interested in following the progress then you can find the source on github.
Speed testing two third party XML parsers for FreePascal and Delphi
Posted 2017-02-06 22:20:51
This article will be comparing the speed of two different third party XML parsers for FreePascal/Lazarus and Delphi. I don't intend on going into great details about features as this is purely to test the speed of parsing a simple XML file.
All testing was done using FreePascal 3.0.0 64-bit using FreeBSD 10.3 on an Intel Pentium P6200 CPU @ 2.27Ghz.
The XML files used in tests are available here (100,000 entries) and here (1,000,000 entries). The XML files are simple records of random names and ages generated using my Random Name Generator (also written using FreePascal).
The the source files for the test themselves can be downloaded here.
For the test I am simply parsing the XML contents into a TList using the following record type:
type
PPerson = ^TPerson;
TPerson = record
FirstName: String;
SurName: String;
Age: Byte;
end;
MYTHcode XML Parser
I have been using MYTHcode XML Parser for many years now, its very simple to use and has always served me well. Sadly, it hasn't been updated in a very long time so if you're trying to use it in a recent version of Delphi you'll probably find it churns out rubbish - it still works perfectly in Lazarus/FreePascal however.
The MYTHcode XML Parser uses a standard style while Next do structure that you're likely to see in other XML Parsers. The parser object is created with a string of the XML as a parameter, as a result the XML is loaded into a TStringList before being parsed.
xml := TStringList.Create; xml.LoadFromFile('namelist.xml'); parser := TXMLParser.Create(xml.Text); while parser.Next do begin if Parser.TagType = ttBeginTag then begin if Parser.Name = 'person' then new(person); if Parser.Name = 'firstname' then person^.FirstName := parser.ContentCode; if Parser.Name = 'surname' then person^.SurName := parser.ContentCode; if Parser.Name = 'age' then person^.Age := StrToIntDef(parser.ContentCode,0); end; if (Parser.TagType = ttEndTag) and (Parser.Name = 'person') then begin people.Add(person); end; end;
The process is quite simple: we check for an open tag, then within that we either create a new pointer to our record type or set the relevant variable to the right value. Because it parsed on a tag-by-tag basis we can always assume the <person> tag has been found in the loops before the 3 tags containing the actual values.
Finally, when we find the closing person tag we are safe to add our record to the TList.
Destructor LibXmlParser
LibXmlParser was a library I found recently when I was forced to use Delphi for a project instead of Lazarus. It does appear to be actively developed and has full support in modern Delphi versions aswell as FreePascal/Lazarus. I am using the non-Unicode version in this test.
This library takes a different approach to parsing where each loop within the scan only focuses on the current XML segment, so the first thing I had to do was create an enum to keep track of where I was within the XML:
type TCurrentTagType = (ttNone, ttFirstName, ttSurName, ttAge);
LibXmlParser does not require the XML to exist as a string before being parsed and can load direct from a file or buffer.
parser := TXMLParser.Create; parser.Normalize := true; parser.LoadFromFile('namelist.xml'); parser.StartScan; while parser.Scan do begin if Parser.CurPartType = ptStartTag then begin currentTag := ttNone; if Parser.CurName = 'person' then new(person); if Parser.CurName = 'firstname' then currentTag := ttFirstName; if Parser.CurName = 'surname' then currentTag := ttSurName; if Parser.CurName = 'age' then currentTag := ttAge; end; if Parser.CurPartType = ptContent then begin case currentTag of ttFirstName: person^.FirstName := parser.CurContent; ttSurName: person^.SurName := parser.CurContent; ttAge: person^.Age := StrToIntDef(parser.CurContent,0); end; end; if (Parser.CurPartType = ptEndTag) and (Parser.CurName = 'person') then begin people.Add(person); end; end;
As you can see in this parser I am having to use the enum to keep track of which tag I am inside of to extract the contents - whilst this is a perfectly valid method it doesn't "feel" natural to me and could turn in to a real nightmare when handling XML that has many fields.
The tests
First up I tested both parsers with an XML file containing 100,000 records:
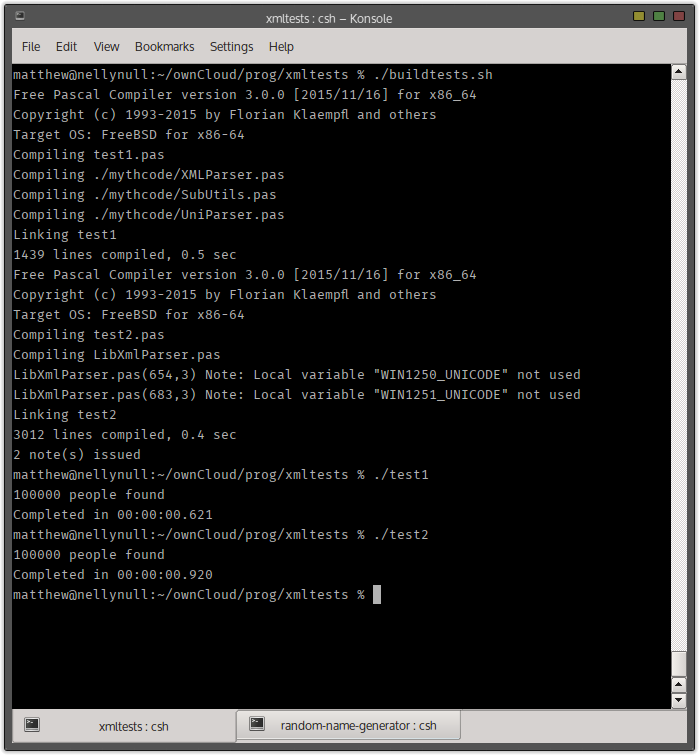
As you can see from the above screenshot MYTHcode XML Parser came out on top by almost half a second. I ran the test again with 1,000,000 records.
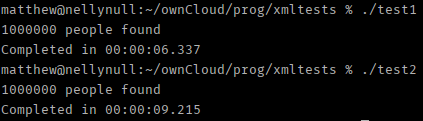
And again the MYTHcode parser came out on top although there were signs of it slowing down: LibXmlParser managed to keep its time almost exactly 10 times that of the first run but MYTHcode ran almost 1% slower with the larger dataset.
Conclusions
The MYTHcode parser, on the face of things, does seem to be faster than LibXmlParser although niether seem to have functionality for loading from streams which means the XML has to exist in memory before it can be parsed; this is an issue when using very large datasets. MYTHcode Parser's downside is that it doesn't appear to be actively maintained so if you're using a modern version of Delphi you'll definitely want to avoid.
At it again
Posted 2017-01-01 21:48:00
Well, as it's a new year I thought I'd have a go at this blogging lark.
Every so often I might have a thought or two about some random subject, and who knows I might even manage to post about it here!
I'm still fiddling with the system - I always liked having the latest application releases on the home page so need to decide how I'm going to integrate those into the blog.